Machine learning approaches toward an understanding of acute kidney injury: current trends and future directions
Article information
Abstract
Acute kidney injury (AKI) is a significant health challenge associated with adverse patient outcomes and substantial economic burdens. Many authors have sought to prevent and predict AKI. Here, we comprehensively review recent advances in the use of artificial intelligence (AI) to predict AKI, and the associated challenges. Although AI may detect AKI early and predict prognosis, integration of AI-based systems into clinical practice remains challenging. It is difficult to identify AKI patients using retrospective data; information preprocessing and the limitations of existing models pose problems. It is essential to embrace standardized labeling criteria and to form international multi-institutional collaborations that foster high-quality data collection. Additionally, existing constraints on the deployment of evolving AI technologies in real-world healthcare settings and enhancement of the reliabilities of AI outputs are crucial. Such efforts will improve the clinical applicability, performance, and reliability of AKI Clinical Support Systems, ultimately enhancing patient prognoses.
INTRODUCTION
Acute kidney injury (AKI) poses significant health and socioeconomic issues, including extended hospital stays, high medical costs, and elevated mortality rates [1,2]. The current AKI definition using the serum creatinine level and urine output has evolved through various clinical trials [3–6]. The NGAL, KIM-1, and L-FABP levels may aid early detection and treatment [7–11]. However, the assays are costly and the utilities of these early marker levels unclear. Also, the levels do not aid the establishment of treatment plans after diagnosis; their clinical utilities are thus limited. Sequential tests are often not scheduled when AKI is not anticipated; the diagnostic contributions of these early markers are thus limited [11–13].
Recently, artificial intelligence (AI) has been used to tackle these limitations [14]. Several studies have used AI to detect AKI early, or to evaluate AKI progression and prognosis [15–18]. However, integration of AI-based AKI systems into clinical practice remains challenging. This review describes the current AI research trends in the AKI context, the challenges posed by model development, and the future integration of AI into AKI research and clinical applications.
THE CURRENT STATE OF AI IN TERMS OF AKI RESEARCH
We searched the Web of Science from 2014 to 2023 using the search terms “AKI” OR “Acute Kidney Injury” (Topic) and “Deep Learning” OR “Machine Learning” (Topic). The numbers of relevant publications exhibited a rapid increase in recent years (Fig. 1). The medical data are those of individual institutions and are often not shared because they are personal [19]. Consequently, we initially focused on information in large public databases including the electronic intensive care unit (eICU) and the medical information mart for intensive care (MIMIC) [20–22]. Recent efforts have sought to refine predictions by the target group (patients in general wards or those undergoing specific surgeries); additional datasets have been built [23–26]. Most authors focused on early AKI diagnosis but some attempted to predict prognosis [27–30]. The results were good; the areas under the receiver operating characteristic curves (AUROCs) ranged from 0.7 to 0.9 [31–33]. However, it is unclear whether such models are applicable in real clinical settings. We describe the trends in AI-related AKI research and the challenges in chapter 2.

The annual numbers of acute kidney injury (AKI) artificial intelligence-related publications.
Labeling issues
Most researchers use the Kidney Disease: Improving Global Outcomes (KDIGO) criteria when diagnosing AKI; these practical guidelines are based on serum creatinine levels and urine output [34]. Consensus statements have been developed to define recovery of kidney function. Acute kidney disease is defined as AKI of stage 1 persisting for more than 7 days but less than 90 days, and chronic kidney disease is diagnosed when kidney function does not recover after 90 days [35,36]. Figure 2 presents a summary of the various AKI diagnostic criteria. Although these are relatively clear, there is no consensus on how to determine whether AKI persists or if kidney function has recovered. Moreover, there are ongoing concerns regarding the use of serum creatinine levels and the estimated glomerular filtration rate (eGFR); it has been suggested that the GFR reserve (the stimulated GFR minus the basal GFR) might be more appropriate, but practical constraints arise when seeking to overcome the limitations of labeling [37–39].
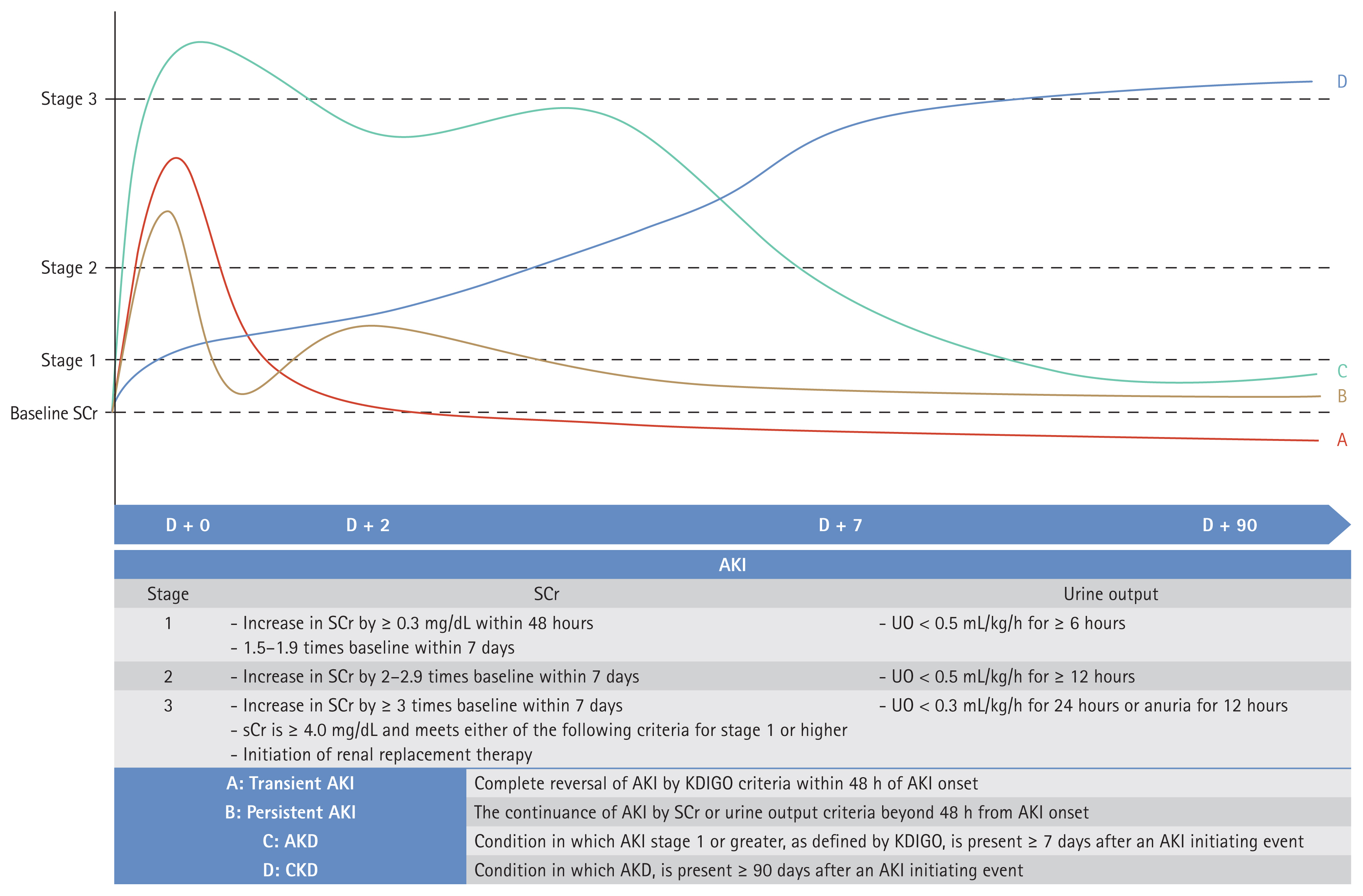
AKI definitions. AKI, acute kidney injury; SCr, serum creatinine; UO, urine output; AKD, acute kidney disease; CKD, chronic kidney disease; KDIGO, Kidney Disease: Improving Global Outcomes.
Most machine learning models are developed and evaluated using retrospective data [40–42]. As such data do not track serum creatinine levels as systematically as do prospective studies, the data are incomplete. This limits our ability to specify the exact timing of AKI occurrence and to define recovery [43,44]. Furthermore, an operational definition based on serum creatinine levels and urine output renders patient identification rather ambiguous, raising various issues. When direct patient interaction is limited, the data are inadequate, and the various criteria are inconsistently used; model reliability is low. Thus, AI model development is challenging. Researchers have often used the most recent serum creatinine value before admission or specific surgery as the baseline level. If data are limited, the serum creatinine level on day 1 is used to predict AKI occurrence from day 2 onwards. When a model is to be applied in real-time, the baseline serum creatinine level is dynamically defined based on measurements taken within a specific time (e.g., 48 hours, 168 hours) or a measurement at a specific point, time is ignored (e.g., The most recent measurement before surgery, within the first 24 hours of admission). If multiple serum creatinine measurements are available, the minimum, average, or most recent value is used [45–48]. Figure 3 shows the serum creatinine records of an actual patient. Depending on the baseline serum creatinine criterion and the research design, the patient may or may not have AKI. Accurate labeling is essential when training models. Although most research is based on the KDIGO criteria, the application of the criteria varies across studies, and this is associated with differences in the AKI status of the same patient; incorrect labeling distorts reality [49–51].
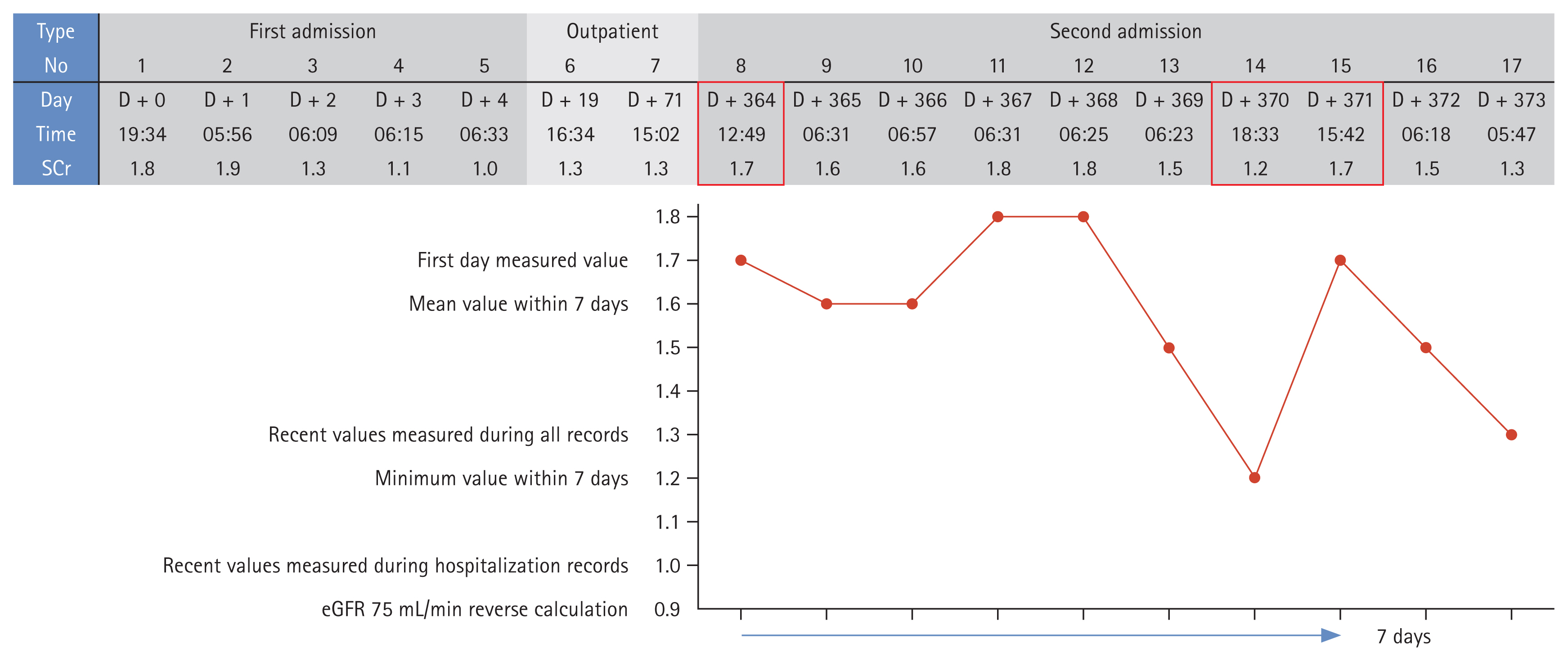
SCr levels and acute kidney injury diagnoses of real patients. SCr, serum creatinine; eGFR, estimated glomerular filtration rate.
The Institutional Review Boards (IRBs) of Soonchunhyang University Cheonan Hospital approved our study protocol (approval numbers: 2019-10-023). The need for informed patient consent was waived by the IRBs as this was a retrospective review of anonymized clinical data.
Other criteria have been used when baseline serum creatinine data are not available. Sometimes, patients lacking such data are excluded. Alternatively, serum creatinine values measured over more than 7 days, or representative values obtained during the hospital stay, or back-calculations based on eGFRs are employed [52–55]. Urine output is rarely recorded in general wards, and only sometimes in intensive care units (ICUs); patients with AKI are thus not ‘labeled’ [56–59]. Of all evaluated AKI cases, only 11% met only the urine output criterion [60]. Moreover, even if the KDIGO criteria are met, it is sometimes difficult to diagnose AKI. Errors in serum creatinine measurements, variations among the measurements, or temporary changes in the levels render it challenging to define the baseline serum creatinine level; the information is fragmented. However, to the best of our knowledge, such situations have not been considered.
Data preprocessing issues
It is essential that the population used for model development is similar to the population to which the model will be applied [61]. Data preprocessing, including the handling of missing and outlier information, is both essential and time-consuming [62,63]. Model development involves definition of the target group, anonymization, handling of outlier and missing data, labeling, and feature selection. The target group characteristics are significantly affected by preprocessing; it is important to describe how the model was developed. The methods used to locate and handle missing data, and the results, must be clearly presented. Such methods include deletion of features or subjects, use of the most recently measured value or a representative value, multiple imputation, model-specific methods, or combinations thereof [64–67]. The method must be practicable, reproducible, and not cause overfitting. For example, if a representative value during the hospital stay is used, how is that value chosen? It may be difficult to find an appropriate value, or the model may be overfitted by the training dataset [68,69]. Some previous studies did not appreciate the importance of missing data handling or did not clearly define the method used. Many works did not even clearly describe the proportions of missing data before and after handling [27,31,70,71]. Care is essential when a model is to be applied in real-time. Depending on the method used to handle missing data, some patients may lack predictive points, leading to overestimations of patient numbers. If multiple imputation is employed, future information that should not be used at earlier points may be employed when handling missing data [72–74]. Figure 4 shows an example of how such situations can lead to overfitting and exaggerated patient numbers, attributable to data leakage during handling of time-series data.
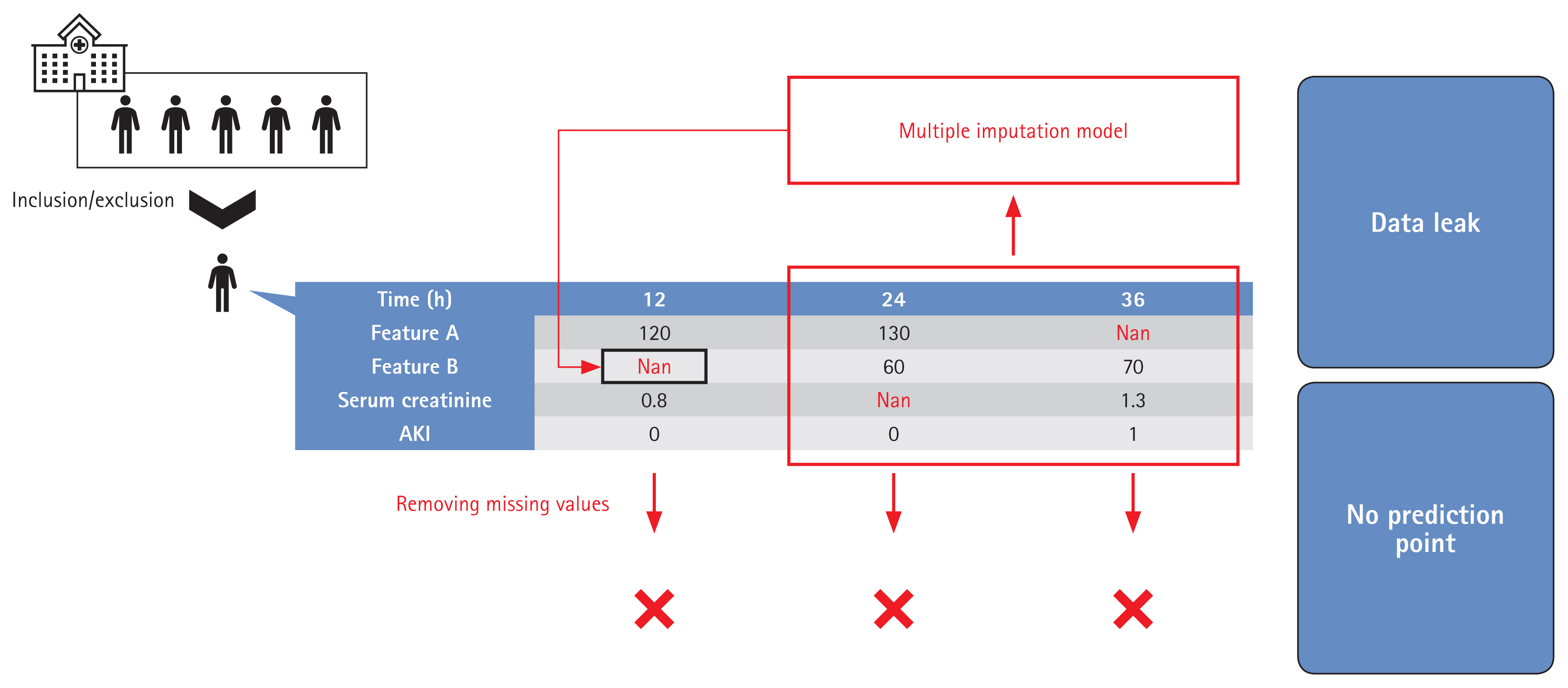
Overfitting and exaggeration of patient numbers caused by data leakage during processing of time-series data. AKI, acute kidney injury.
Model evaluation issues
Machine learning models discover hidden patterns in training data but can become overfitted by the data [75,76]. Patient populations vary among hospitals, and the data characteristics vary by the equipment used and/or the prescribing practices of physicians [77,78]. Moreover, factors such as the frequencies of infectious diseases (example: COVID-19) change over time, and the continuous development of new drugs and surgical methods change the nature of the data over the years [79,80]. However, many studies employed only single cohorts and, to the best of our knowledge, very few models considered temporal changes [35,81,82].
Most model outputs are performance metrics. Performance is measured in various ways, including Accuracy, Precision, Recall, the F1 value, the AUROC, the area under the precision-recall curve, among others, but the limitations mentioned above complicate the evaluation of models based solely on these metrics. The data used for performance evaluation, and the labeling methods and preprocessing methods, differ; it is meaningless to seek to compare model performance. Moreover, when handling a data imbalance during AKI model training, sampling not only of the training data but also the entire dataset can distort the performance metrics. For example, if data imbalance is severe, Recall and Precision are important evaluation metrics. In such cases, as shown in Figure 5, the Precision varies by the sampling method. Table 1 summarizes the key points made above. Full model or code details were also considered important, but very few studies publish them [18,56,60,83,84]; these elements have been excluded from the Table. More references can be found in Supplementary Table 1.
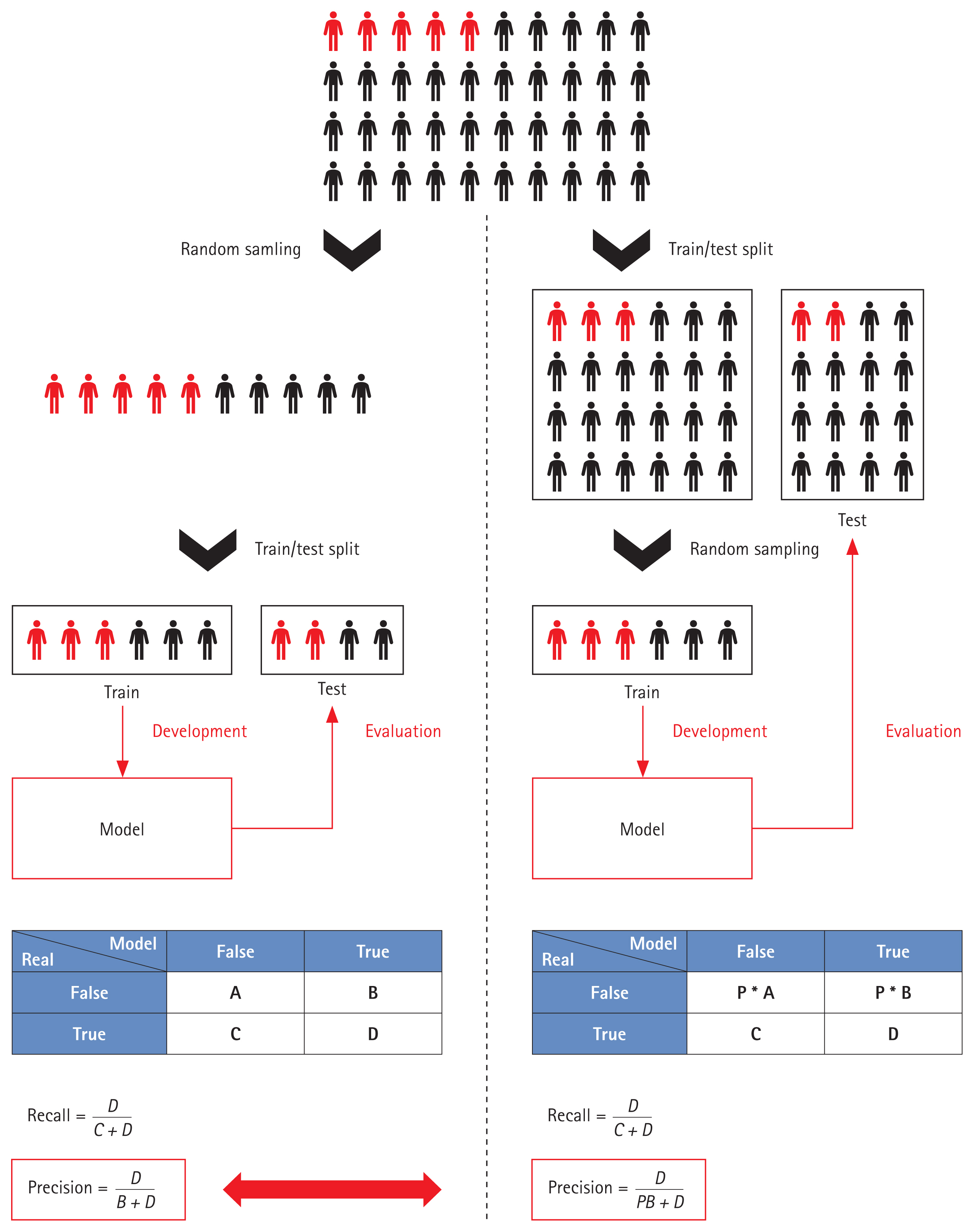
Variations in performance evaluation by the sampling method employed. Red, diseased populations; Black, non-diseased populations.
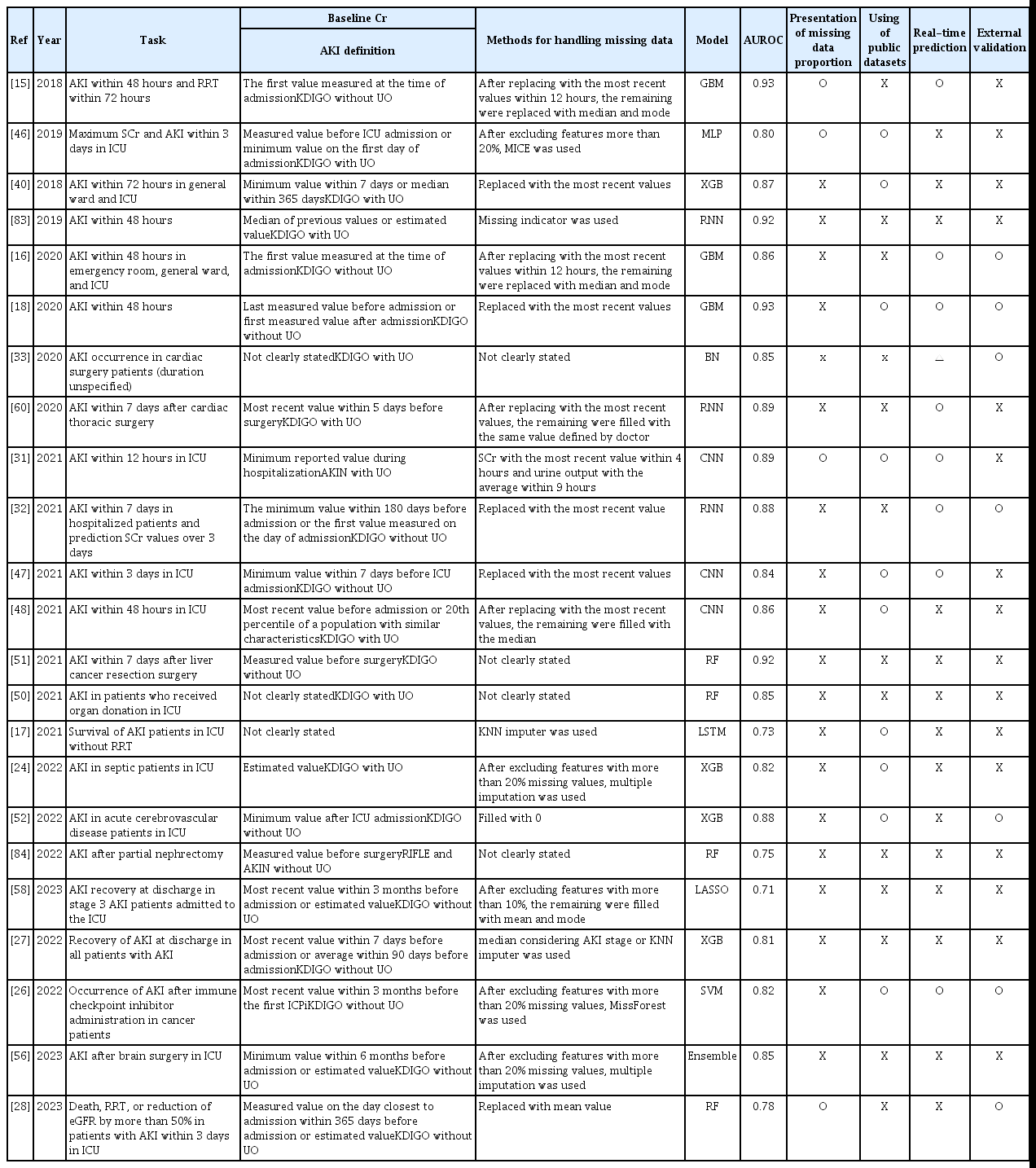
Previous studies using artificial intelligence to predict acute kidney injury
FUTURE DIRECTIONS FOR AKI AI RESEARCH
Consensus labeling standards and evaluation data
Clinical guidelines for AKI diagnosis aside, it is clear that consensus AKI labeling standards are needed for machine learning models that use retrospective data. A scientific approach and verification of clinical effectiveness are essential when the numbers of serum creatinine measurements over time vary. The use of different standards renders it difficult to compare and evaluate models. Consistent, rational labeling guidelines are essential. Ideally, a multinational, multi-institutional dataset, labeled using agreed standards, would be employed for performance evaluation of all models. Large medical databases such as eICU and MIMIC have accelerated the development of medical AI [85–88].
Multicenter studies and use of the latest technologies
High-quality data are essential. Sparse data do not well-train models and may introduce bias toward specific groups or cause data overfitting [89,90]. When developing medical AI, consideration of patients with diverse characteristics, treated in various institutions, enhances model training [91]. However, medical data are difficult to obtain and use because of legal issues and the need for quality assurance [78,92]. Thus, federated and transfer learning are being actively researched. During federated learning, models or weights (but not data) are shared among institutions for model training. Transfer learning takes a pre-trained model and develops a new model based on that model. Both methods largely lack data security issues and effectively train models even when the data are limited [93–96]. This ensures that the cohorts used for model development are diverse. Meta-learning can overcome problems associated with among-cohort differences during model development [97], and quantifies such differences and their impacts [18,98].
Currently, most research is focused on early AKI prediction. Only a few studies have used machine learning to predict AKI prognosis [99]. This may require rather long observation periods and/or extensive serum creatinine records. No consensus recovery criteria are available; it is difficult to predict AKI prognosis. Efforts to overcome these limitations include increasing the data volume via transfer and/or federated learning, and the use of multitask learning models [100]. It is important to monitor advances in machine learning continuously and apply them in the AKI research field. Figure 6 shows the latest AI technologies.
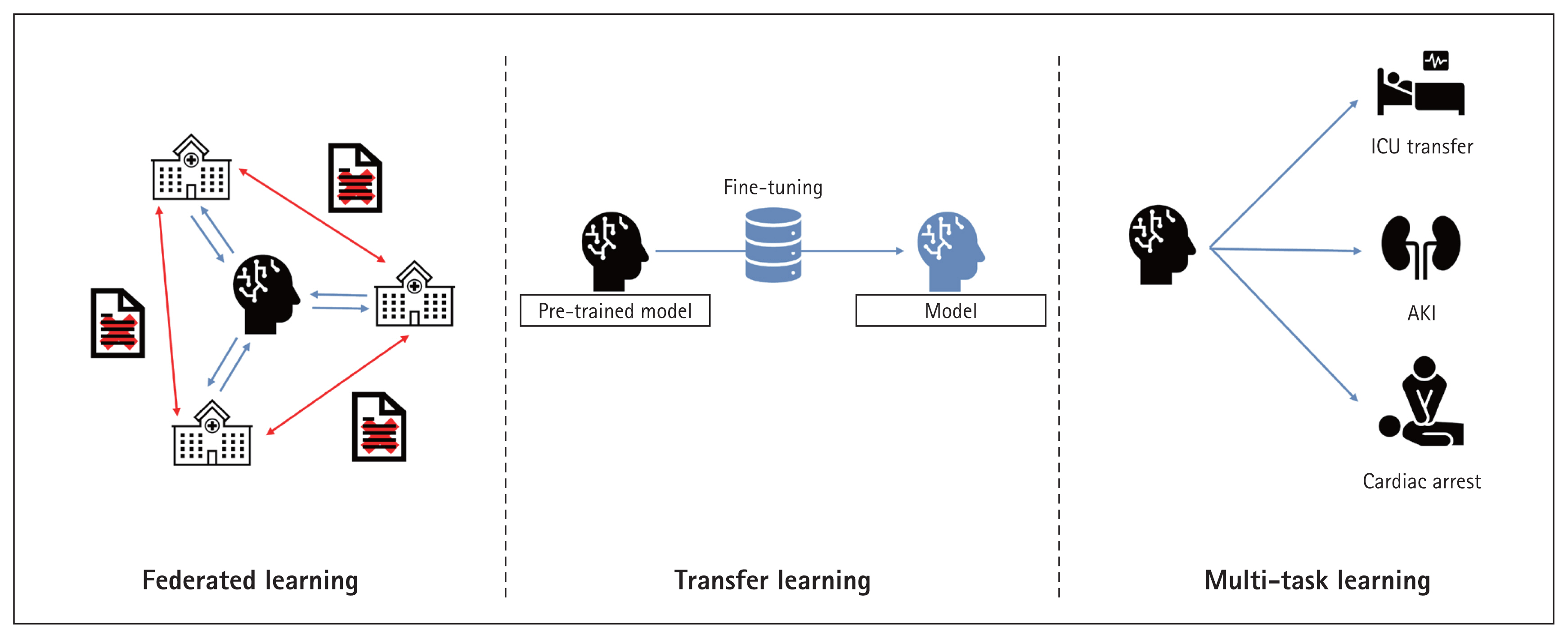
The latest artificial intelligence approaches. ICU, intensive care unit; AKI, acute kidney injury.
Model evaluation methods employing real users
Medical AI is meaningful only when it helps physicians and patients. Both time-based performance and external validations should be considered. All models should be thoroughly reviewed in terms of real-world effectiveness when predicting primary outcomes such as AKI occurrence or recovery, death, the hospital stay, and a need for ICU transfer. Comparing models to physicians who seek to solve the same tasks could be a useful alternative; this is frequently employed in the medical imaging AI field [101,102]. Rank et al. [60] found that AKI models outperformed physicians in terms of predicting AKI onset. However, tabular data are less informative than the information used by physicians [60]. Therefore, rather than comparing models with physicians, comparisons of physicians who do and do not use models might be better. Research on AI-based clinical decision support systems is ongoing.
Henry et al. [61] developed an AI model predicting sepsis onset, invited clinicians to use it, and conducted semi-structured interviews with 20 clinicians 6 months later. Prospective model evaluation after model introduction may be effective. Models should be continuously improved via user feedback and the results of prospective evaluations. The use of many features renders applications difficult; too much data are required [89,103]. However, if too few features are employed, a physician might have few options even if the model is accurate. Previous studies employed 15 to 1,000 features [18,104]. Useful features should be continuously sought based on model performance and user feedback. Figure 7 shows advanced model evaluation methods.

Several advanced models used for patient evaluation. CDSS, clinical decision support system; AKI, acute kidney injury; ICU, intensive care unit.
Explainable AI and causal inferences
Even if model performance is excellent, AI complexity (the ‘black box problem’) is a major obstacle to clinical applications [105]. The inner workings of a model are opaque; it is impossible to trace decision-making. In a ‘white box’ model, all operations are completely transparent, thus all steps from inputs to outputs. Many studies have sought to make black boxes white [106]. The advances range from an emphasis on simple feature importance to Local Interpretable Model-agnostic Explanations, SHapley Additive exPlanations, Partial Dependence Plots, Individual Conditional Expectation Plots, and combinations thereof [107]. However, these methods do not show how features cause certain decisions to be made. Proof of causality, as opposed to proof of mere correlations or trends, is extremely challenging. It is crucial to derive correlations between various patient features and AKI [108,109]. Meta-analyses are aimed at strong associations between certain features and AKI occurrence or recovery, enhancing confidence in models that use such features [110]. AI researchers currently seek to create an Artificial General Intelligence that thinks like humans. A new AI should consider various modalities, not only fragmented information [111]. Although model interpretation may be difficult, multimodal technologies that combine tabular data with images or natural language, and generative AI technologies, could serve as alternatives to black boxes and prove difficult causalities [112]. Explanations of models using intuitive and human-friendly methods would greatly benefit users.
Simple laboratory parameters or vital signs can aid diagnoses and, thus, appropriate interventions by physicians [113]. For example, if AKI patients are identified early, physicians can adjust drug prescriptions or surgical schedules accordingly. This alleviates the burden on medical personnel who manage AKI and mitigates the differences between regions with good and limited medical infrastructures. Physicians must thoroughly review features that could enable more proactive interventions, such as diseases apparent on admission; the indications for the planned treatments/surgeries; and the medication types, quantities, and dosing schedules [114,115]. Consideration of such features during model development and interpretation would not only facilitate early diagnosis and intervention but also the development of an AI that truly supports clinical decision-making, thus beyond simple early detection (Fig. 8).
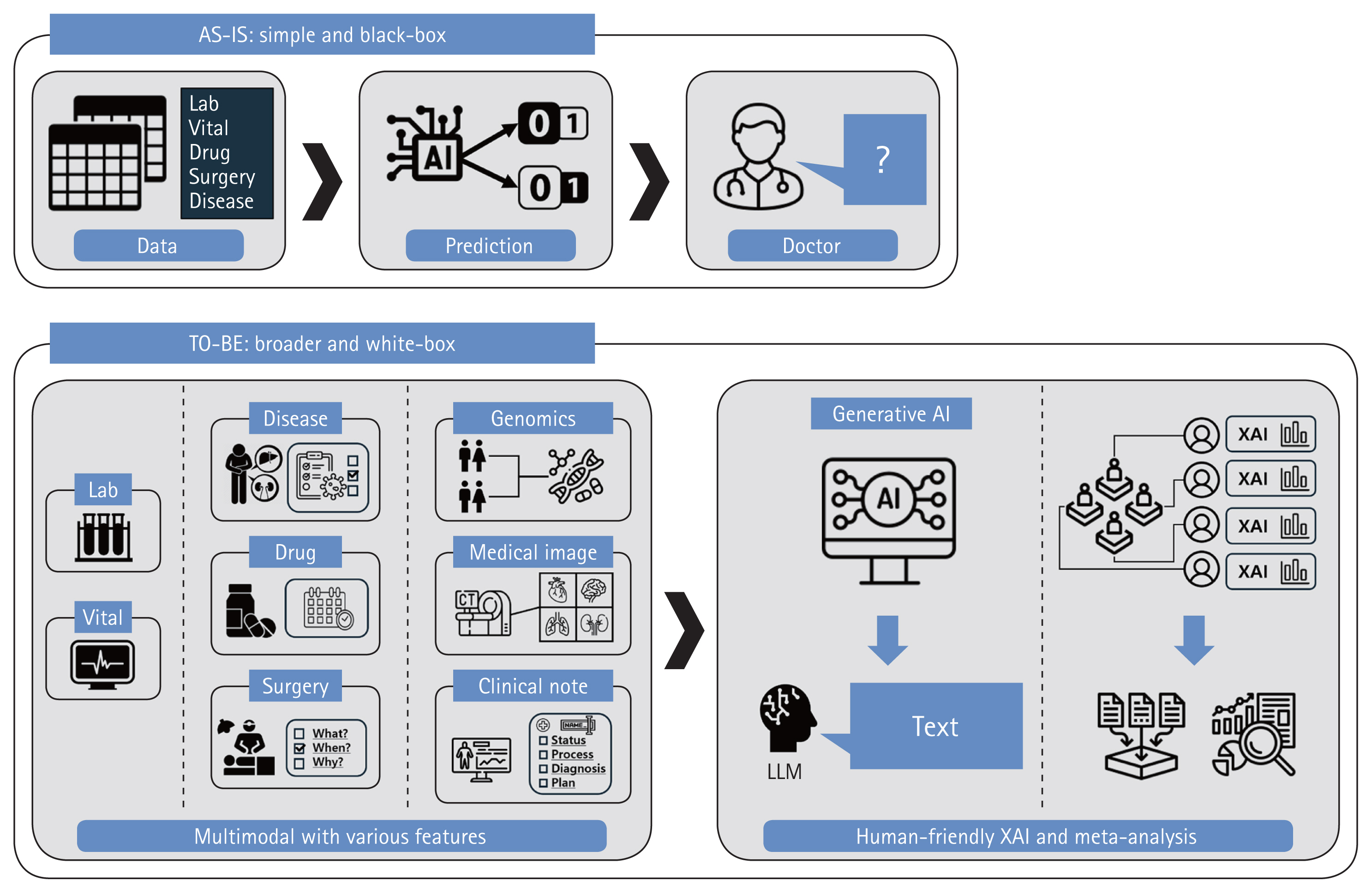
How to develop a reliable and clinically meaningful model. AI, artificial intelligence.
CONCLUSION
AI will greatly advance the practice of medicine. Many medical AI studies are in progress. In the AKI context, many works have reported high-level AI performance, confirming the potential of machine learning in terms of early AKI diagnosis and prediction of prognosis. However, medical AI is patient-intrusive; care is required. Many obstacles remain. It is time to move out of the computer laboratory into the clinic.
Notes
CRedit authorship contributiones
Inyong Jeong: resources, investigation, data curation, writing - original draft; Nam-Jun Cho: resources, investigation, data curation, writing - original draft; Se-Jin Ahn: data curation, visualization; Hwamin Lee: conceptualization, methodology, investigation, data curation, writing - review & editing, funding acquisition; Hyo-Wook Gil: conceptualization, methodology, resources, investigation, data curation, writing - original draft, writing - review & editing, funding acquisition
Conflicts of interest
The authors disclose no conflicts.
Funding
This study was supported by the Soonchunhyang University Research Fund.